With the Nebula Creator, everyone can finally use Nebula for free – regardless of whether you’re already an Origins user or not. The Creator is a free desktop software that prepares point cloud projects for online visualization in Nebula.
How it works
Download the Creator. Convert your point cloud data and add panos if you wish. Then simply follow the usual Nebula workflow. Done!
As promised, we are continuously expanding the number of cloud services that can be connected to Nebula. Due to strong demand, this update introduces support for AWS.
How it works
In the video, we show step by step how to connect your AWS account to Nebula – even without extensive IT knowledge. The short version? Just follow the instructions laid out in Nebula.
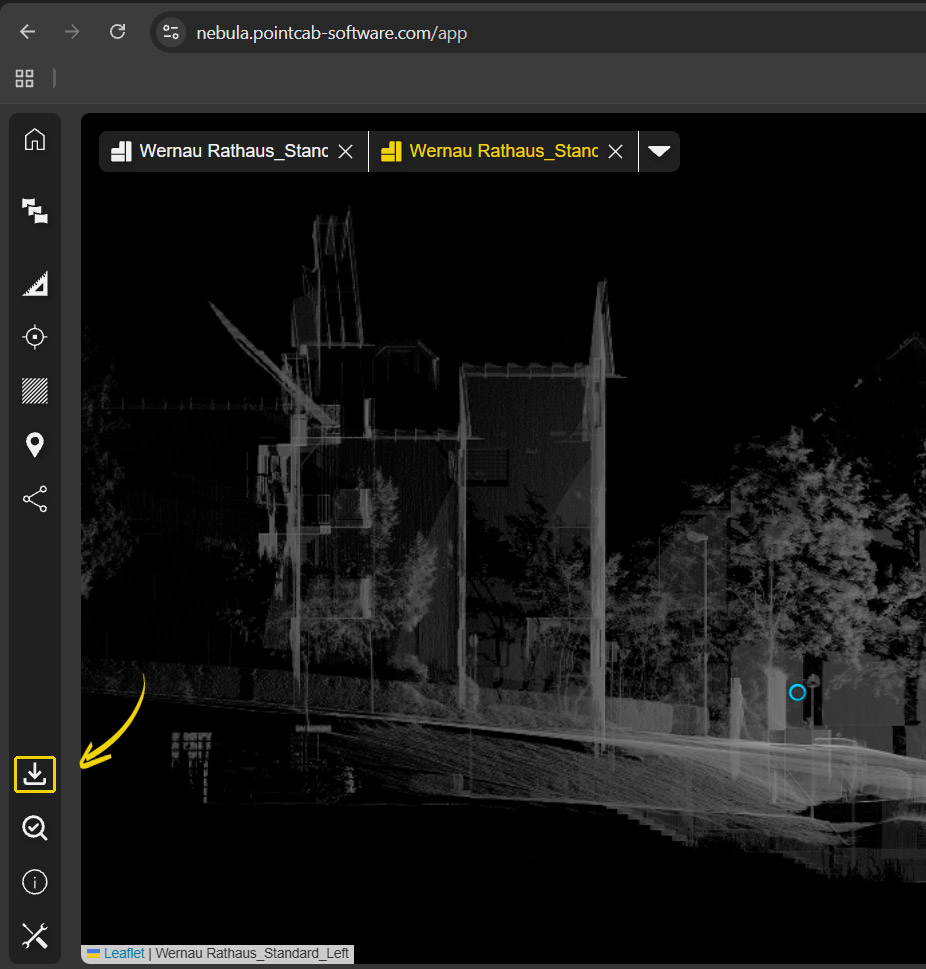
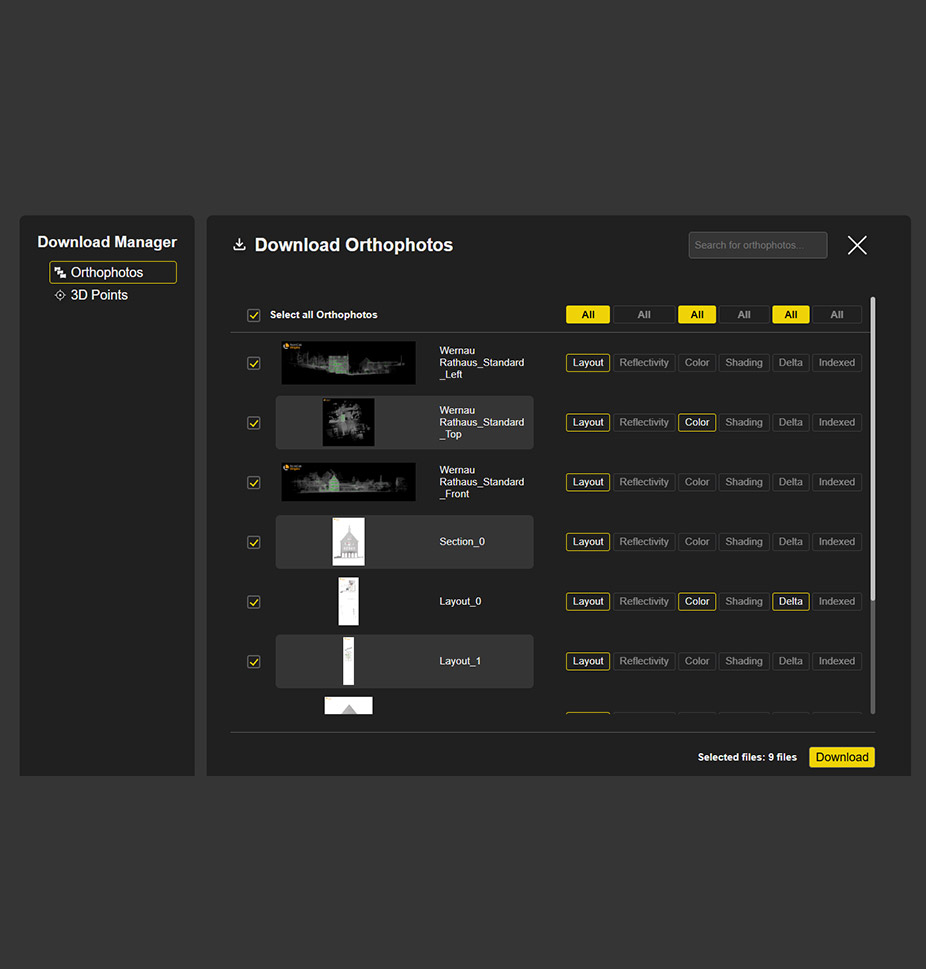
New Download Manager
What it’s for
Our new Download Manager allows you to download orthophotos and 3D points directly in the browser – a long-awaited feature. This allows you not only to visualize results, but also to easily share them.
How it works
Click on the Download Manager icon in the menu at the bottom left. Select the desired orthophotos or 3D points in the new window. Click on “ALL” to select all available files at once. Simply click on Download – done.
Height and Cluster Navigation
What it’s for
To make navigation in Nebula even more intuitive, scan positions can now be filtered and displayed by height or cluster.
How it works
The video includes a detailed explanation. The short version? Simply filter by height or cluster and show or hide scan positions as needed.
"Display Range" Option in Bubble Views
What it’s for
The perfect complement to the new height and cluster navigation! The “Display Range” function allows scan positions to be shown or hidden based on their distance from your current viewpoint in the Bubble View.
How it works
Simply select the distance from which scan positions should be displayed via the menu in the top right corner.
Measurements & POIs in Bubble Views
What it’s for
Another great enhancement for the Bubble View: measurements and POIs can now also be created directly within the Bubble View.
How it works
Download the coordinates, then use Ctrl + mouse click to measure distances and 3D points. Of course, POIs can also be enriched with additional links and documentation.
3. Nebula 2.1 – More New Features
Cube Navigation in 3D Point Cloud View
Option to re-arrange Slots
New Default Setting: Choose between Pano or Bubble View
4. Nebula 2.1 – Refinements and Fixes
Improved clipping box handling
Improved Settings behaviour & appearance
Improved workflow for purchasing additional slots
Improved 3D Visualization
Improved Mini Map for easier navigation
Extended measurements units (feet)
Dynamic point-display adjustment for improved performance
Optimized point cloud loading for faster performance
Fix: Updates are synchronized in real time across all views
Fix: Unified sharing links for all users
Fix: Automatically update public links
Fix: Microsoft SharePoint Public Links
Fix: Sidebar issues in Firefox
Book your demo today!
Want to see those shiny new features first-hand?
Simply book a free, no-obligation demo with one of our support engineers below.
Want to keep up with the latest pointCab news?
Then follow us on Social Media or subcribe to our newsletter!
After battling with cancer for almost 6 years, our CEO and Co-Founder, Dr. Richard Steffen, has passed away peacefully, surrounded by his loved ones, on July 22nd. In this Obituary, we would like to reflect on the person he was and the impact he has made on the lives of those surrounding him.
Death always comes as a shock. Although in Richard’s case, there was some time to prepare, one is never truly prepared for losing someone close to one’s heart. And Richard was just that, close to all our hearts. He was more than the CEO of PointCab. He was a son, a brother, a husband, a father, and one of the most loyal and caring friends one could have.
Richard's life before PointCab
When Richard was born in 1976 in Schwerin, he was born into a divided Germany, in a country that no longer exists. Nevertheless, he enjoyed a happy childhood, surrounded by two loving parents and a loving sister. In 1984, the family moved away from the city to his grandparents’ farm in Dietrichshagen – a wonderful place for a child to grow up. There, he spent his formative years and graduated from high school with a degree that enabled him to pursue a higher education. In between all of that, the Berlin Wall fell, and Richard was suddenly living in a different country, without even changing his address.
Now free to move anywhere, he decided to study Geodesy in Hannover, but not before he did his mandatory military training in the Bundeswehr. Degree in hand, Richard immediately founded his first company with a partner from Magdeburg. It only lasted one and a half years, but it goes to show what kind of person Richard was: Full of ideas and confidence, bestowed by a unique drive to change things. Parallel to this, he also took a course in Computer Science, deepening his coding skills. Undeterred, with a mind that simply can not tolerate standing still, the next logical step for Richard was to take on a new challenge head-on. Consequently, he decided to obtain his Ph.D at the University in Bonn. He spent 6 years there, becoming an expert in Geodesy, Geoinformation, Photogrammetry, Computer Vision, and Adjustment Calculations. It was also there that he formed a close relationship with his PhD advisor and mentor, Prof. Dr. Förstner, whom he would always hold in high regard.
Ready to switch things up again, and with a deepened passion for coding, he decided to take on a job at the University of Chapel Hill, North Carolina, in the Department of Computer Science. While he was there, some old friends reached out to him with an idea for a point cloud processing software. They needed a capable developer with a deep understanding of Geodesy, and Richard was just the right fit. For a while, he worked on the software and as a researcher at the same time. However, in 2011, he decided to go all in and become self-employed. This was also the year the first version of the PointCab software was released, as a product of Laserscanning Europe. In 2013, the software was successful enough to warrant the founding of an independent company, and Richard became a co-founder of PointCab GmbH. After his partner left the company in 2014, Richard assumed the role of CEO.
Richard's Impact at PointCab
Those early years were marked by struggle, but also a lot of fun. With PointCab, Richard found a project he could pour all his heart and his creative energy into. He would often code and research for hours on end, living off frozen pizza and little sleep. His mind would thrive on solving the next puzzle, the next challenge, and he just could not stand occupying it with “mundane” things like cooking, shopping, or dealing with the bureaucracy that comes with being a CEO. Acutely aware of this, he started hiring the first employees for administration and support as soon as the company’s turnover would allow for it. He fortunately could also lean on Dr. Ulrich Franz, his business angel and shareholder, to help with strategy, marketing & sales in those early days.
Over the years, Richard was able to hire more people and build the fantastic team that is PointCab today. He rarely interfered with the decisions his team made in their respective areas of expertise, and not for a lack of understanding. On the contrary, Richard was able to delve into virtually every topic and come out on top. However, he would always trust in his team and their skills, and as a bonus, this enabled him to spend more time on the topics that innately fascinated him. With a steadily growing team, he made his dream come true and bought a houseboat in the port of Hamburg in 2015. He also started to take prolonged trips to Vietnam, a country he was always intrigued by, and where he met his wife.
With his team in Wernau near Stuttgart and him spending most of his time in Hamburg or Vietnam, it might sound like he wasn’t contributing much anymore to the company, but this couldn’t be further from the truth. He regularly visited the office and rarely missed a team meeting. He would always work on the hardest problems and spend hours (preferably) with his Dev-Team to solve them together. He was an avid mentor, especially to Martin, now our CTO, and encouraged him to pursue his Ph.D. as he encouraged all of us to keep learning and to grow.
In between all of that, he also managed to form deep personal relationships with all of us. He’d ask how things are going, and you could be sure he’d catch up on it the next time you talked. If you were up for it, he’d get into the wildest debates with you about any topic. You could hold a vastly different opinion on the matter, and at the end of it, the two of you either managed to broaden your horizons or agreed to disagree. However, debating with Richard never negatively affected your relationship – on the contrary, most of the time, it deepened it. A quality rarely seen in our modern times. All of this made him more than just our boss. It made him our friend and one of the fiercest and loyal friends one could have. He would celebrate our private milestones with us, like a wedding or buying a house, but he would also help us through the tough times. When someone had a health problem, he fought for them to get all the coverage and benefits available, and he made sure to let them take all the time they needed. Their job still waiting for them when they returned. Therefore, disregarding all his flaws when it came to the “mundane”, Richard managed to become a true leader. This incredibly wonderful guy you could trust.
The last Chapter
Consequently, it came as a great shock for all of us when he was diagnosed with terminal cancer in 2019. At the time, the doctors gave him about one more year to live. However, being the way he was, he also confronted his cancer head-on. He managed to find great doctors, working out a treatment plan with them and keeping the cancer at bay. No matter how hard things got, he would do it all with incredible grace, ploughing on. All the while living his life to the fullest, still traveling between Vietnam and Germany and keeping up with everything else.
In 2021, facing the pandemic and travel restrictions, he finally decided to settle down and marry his beloved girlfriend. She had been an incredible source of support for him throughout this time and was always right by his side. With her and his step-daughter, he moved permanently to Germany and bought a house in Rostock, close to his grandparents’ farm in Dietrichshagen, where he grew up and his parents still live. He started to prioritize his health and treatments even more, as well as spending more quality time with his loved ones.
After trying to juggle these priorities with work for a while, he realized he had to step back more at PointCab. Even he couldn’t do it all. Talking to his right-hand man since 2016, Chris (COO), they formed a plan in 2022. Martin, his protege, would become the CTO and take over Richard’s responsibilities for the development of the software. Nicole, with a knack for strategic thinking and organisation, would become the CMO. Richard was confident that, together with Chris, the three of them would be able to lead the company – and so they did.
Slowly but steadily, Richard handed over most of his responsibilities. This allowed him to spend more time with his family, only working on the things he actually enjoyed. Furthermore, his health seemed to pick up again, particularly in 2024. The cancer was still there, but it seemed manageable. It was something he had learned to live with by now, and he never wanted to be seen as his illness but as the person he was. It was an exciting and happy time for all of us. Richard seemed invincible. There he was, roughly 4 ½ years after his diagnosis, defying the odds and living his best life.
But cancer is a *****. It does not debate. It does not agree to disagree, and it has a habit of returning when you least expect it, even uglier than before. Unfortunately, this was the case for Richard in spring 2025. The doctors found that the cancer had spread once again and aggressively. Once again, the diagnosis was dire. This time, they were talking weeks or months. However, who could blame us for not wanting to believe this and cling to hope? At this point, Richard seemed like Superman. Defying all odds, he’s made it this far, so why not once more? But this time was different, and looking back, it seems like he knew it too.
While he put most of his affairs in order a long time ago, he never put too much pressure on finding a new CEO for PointCab. However, this time was different. He almost immediately reached out to his old friend and business partner, Eric Bergholz. As the CEO of Laserscanning Europe, PointCabs’ sister company, he was involved in the creation of the PointCab software. He was there when the company was founded, he knows the team, and he saw it grow. Since Richard was also a shareholder of Laserscanning Europe, they spent plenty of time discussing strategies for both companies. Last but not least, Richard and Eric were very close friends. There was hardly anyone else he would trust as much as Eric to continue his legacy. Assured by Richard that his leadership team was in place and had successfully managed the company for the last few years, Eric gracefully agreed to take on the role as the new CEO of PointCab.
The team was informed of this decision, although, as per Richard’s wish, his health was not cited as the main reason. While the clogs were working in the background to ensure a smooth transition, his health rapidly declined. Just a few days before his passing, he had been writing to Martin about a new research project. Then it all happened really fast. His palliative care team came to his house and ensured he was as comfortable as possible. Luckily, there was enough time for most of his friends and family to say goodbye. He passed away in his sleep, in his own house, surrounded by his loved ones. Until the very end, that uniquely sharp mind of his was still working, solving puzzles. In our grief, that’s something we are thankful for and take comfort in.
If you have read this far, thank you. In the face of tragedy, one can feel incredibly powerless and helpless. So telling Richard’s story is important to us. Not only to remember him and his legacy, but to inspire. His example taught us how to lead with compassion, to burn for our passions, to fight uneven odds, and so much more. It will stay with us forever. Maybe you can learn from it, too.
The Architecture, Engineering, and Construction (AEC) industry stands at the forefront of shaping our built environment. In our series “The AEC Impact” we explore the myriad ways in which the industry contributes to societal well-being, environmental sustainability, and economic growth. Join us as we uncover the transformative power of the AEC industry and its pivotal role in building a brighter, more sustainable world.
How Laser Scanning Supports Conservation
From remote rainforests to urban green spaces, laser scanning technology helps researchers and organizations in many different ways:
Monitor forest health and deforestation → High-resolution scans can detect subtle changes in vegetation over time.
Create digital twins of natural landmarks → This helps preserve vulnerable ecosystems and supports restoration after natural disasters.
Track erosion and water levels in riverbanks and coastal zones → Accurate 3D models allow experts to assess risks and plan interventions.
Document caves, cliffs, and fragile habitats without physical contact → Non-invasive scanning helps protect areas where human presence might cause damage.
Giving Old Buildings a Greener Future → Scanning existing buildings helps to restore them in an energy-efficient way, also saving precious resources by not building new structures
These projects often involve interdisciplinary teams: ecologists, engineers, architects, and geospatial experts working together.
Real-life examples: Protecting Dune Ecosystems in the Netherlands
In the coastal dunes of Vlieland, an island in the Dutch Wadden Sea, researchers used LiDAR combined with aerial imagery to map the spread of invasive shrubs like Prunus serotina and Rosa rugosa. These species threaten native dune biodiversity, but detecting them manually across large, shifting landscapes is difficult and resource-intensive.
By incorporating LiDAR-derived canopy height data into their analysis, the team improved their detection accuracy by more than 10%, enabling more targeted removal and less environmental disturbance.
“The use of LiDAR improved classification of shrub cover substantially, especially in detecting higher-density patches.” — Van Iersel et al., Remote Sensing in Ecology and Conservation (2020) 🔗 Full Report (Open Access)
This approach helps preserve native dune flora and fauna while reducing the need for broad mechanical or chemical interventions.
Real-life Examples: Scottish National Portrait Gallery
In the Scottish National Portrait Gallery, Edinburgh 3D laser scanning captured the entire structure of the historic building in precise detail. Then a BIM model was created, helping to plan renovations without damaging original features. It also enabled detailed analysis of thermal bridging, structural conditions, and spatial coordination for new systems. This lead to:
Improved insulation and air tightness without compromising heritage elements
Integration of energy-efficient lighting and HVAC systems
Achieved a 14% reduction in annual CO₂ emissions, contributing to overall better energy performance while maintaining historical integrity
Laser scanning was essential in balancing heritage preservation with modern energy standards.
These successes weren’t born from gadgets alone. They reflect the dedication of surveyors, ecologists, engineers, architects, and technicians. Their expertise ensures technology serves both people and nature.
On World Nature Conservation Day, their quiet yet crucial contributions deserve our deepest gratitude.
Want to keep up with the latest pointCab news?
Then follow us on Social Media or subcribe to our newsletter!
Real-world support cases explained – one point cloud at a time.
In this series, we take a closer look at real questions and challenges that come up when working with point cloud data. Each post is based on an actual support case and breaks down what happened, why it happened, and how to solve it, step by step.
But we don’t stop at troubleshooting. Along the way, we explain the background behind the tools, terms, and technologies involved.
The Questions that sparked this Post
A user asked us a great question:
Is there a way to reverse the transformation applied to a project in Origins, especially if I want to maintain georeferencing for modeling in Archicad?
She mentioned seeing a “trick” referenced in one of our webinars, but couldn’t find it again. Since this topic comes up regularly – especially with BIM workflows – here’s a detailed guide for anyone modeling in Archicad with georeferenced point clouds.
What Is Georeferencing – And Why It Matters in Archicad
Before diving straight into our solution, a little background info on georeferencing might be in order:
Georeferencing is the process of aligning spatial data (like point clouds) with real-world geographic coordinates, such as UTM or Gauß-Krüger systems. When a point cloud is georeferenced, every data point corresponds to a precise location on Earth. This is critical in AEC workflows for aligning scan data with GIS, survey data, or construction site coordinates.
In theory, this georeferenced data should integrate seamlessly into CAD or BIM software. But in practice, large coordinate values (often in the millions) can break things.
The Challenge: Large Coordinates vs. Modeling Performance
Point clouds in georeferenced coordinate systems often contain large values far from the origin (0,0,0). CAD tools like Archicad and Revit don’t handle these large coordinates gracefully. This can lead to:
Laggy or unresponsive modeling
Display glitches
Broken geometry or snapping issues
Inaccurate scaling or alignment
So how do you preserve georeferencing and maintain smooth modeling in Archicad?
The "Trick": Temporary Translation Instead of Permanent Transformation
Here’s how to maintain georeferencing while still working in a performant local coordinate system:
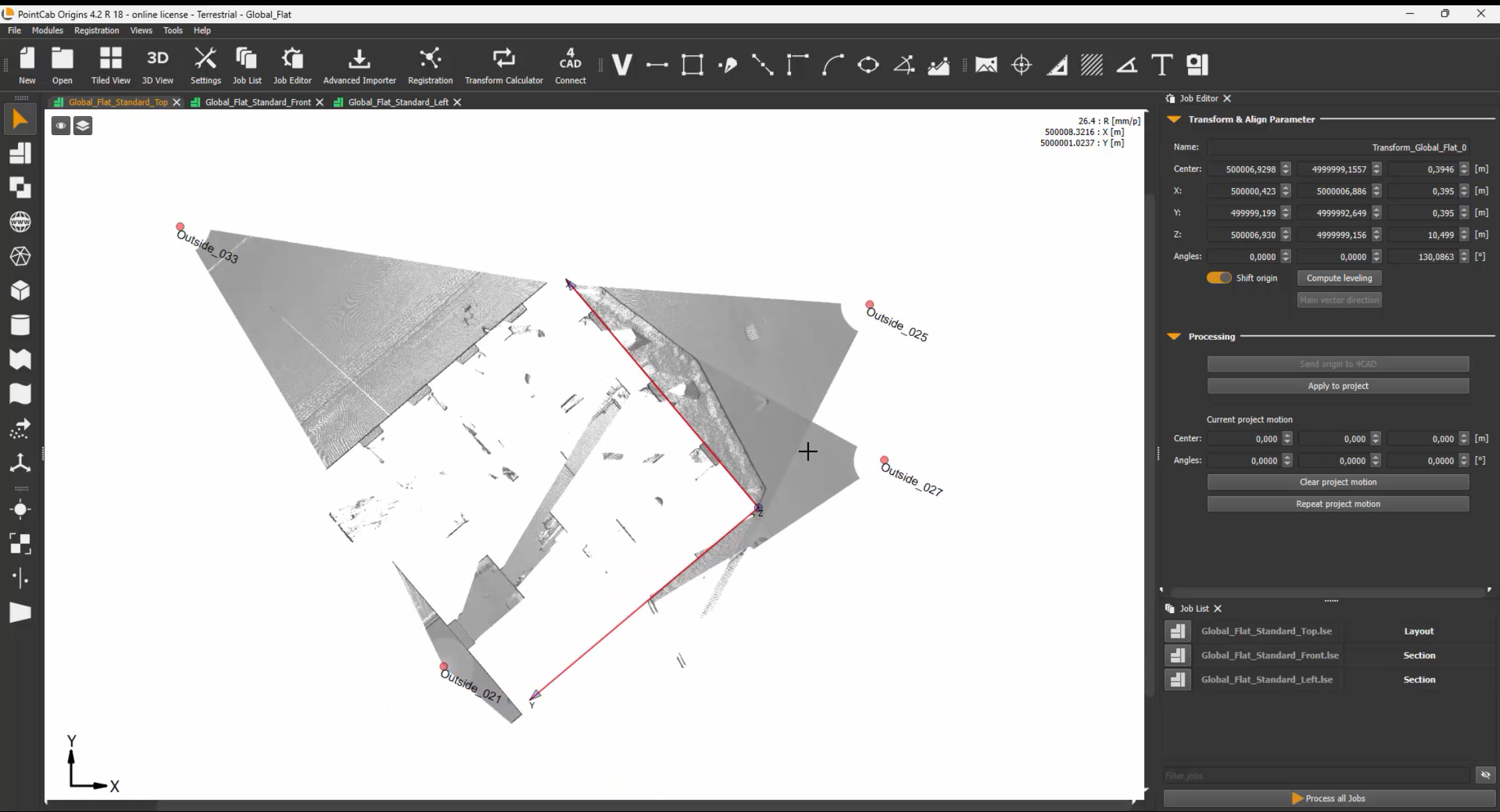
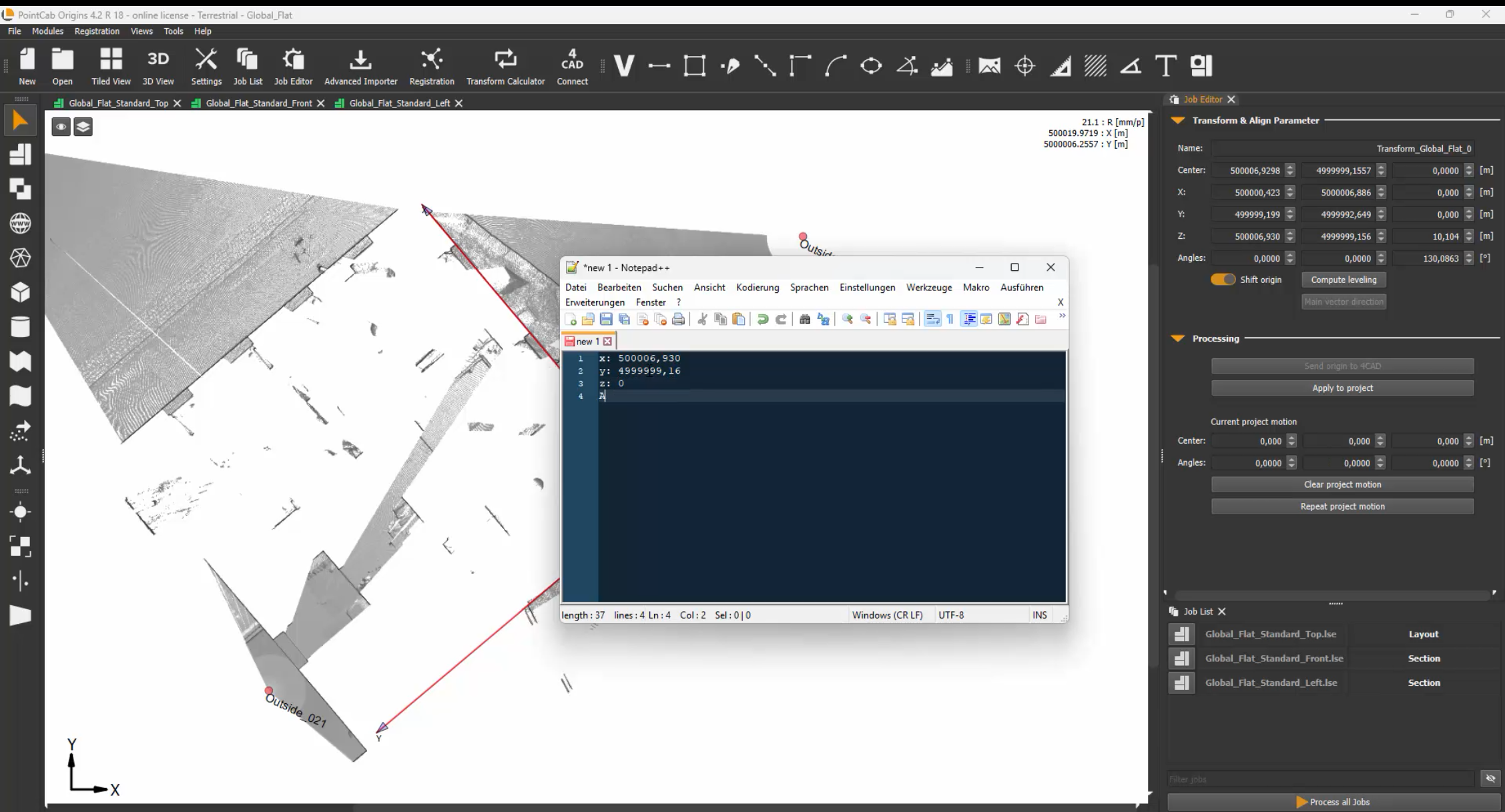
1. Avoid Full Alignment with Rotation When transforming your project in Origins, don’t use full rotation/alignment unless absolutely necessary. Instead, use the Align Tool to apply a translation – a shift in position and rotation around the Z-axis. The rotations around the X and Y axes should be avoided. Enter these parameters as the Survey Point in Archicad.
Pro tip: Use round, memorable shift values. Example: If the original X coordinate is 3,500,357.000, shift it to 0 or another clean number to simplify your local modeling.
2. Document the Shift
PointCab Origins automatically stores transformation values in the Align Protocol. Take a screenshot or note the exact shift values, so you can later reverse the transformation. These values will be crucial when re-georeferencing the model.
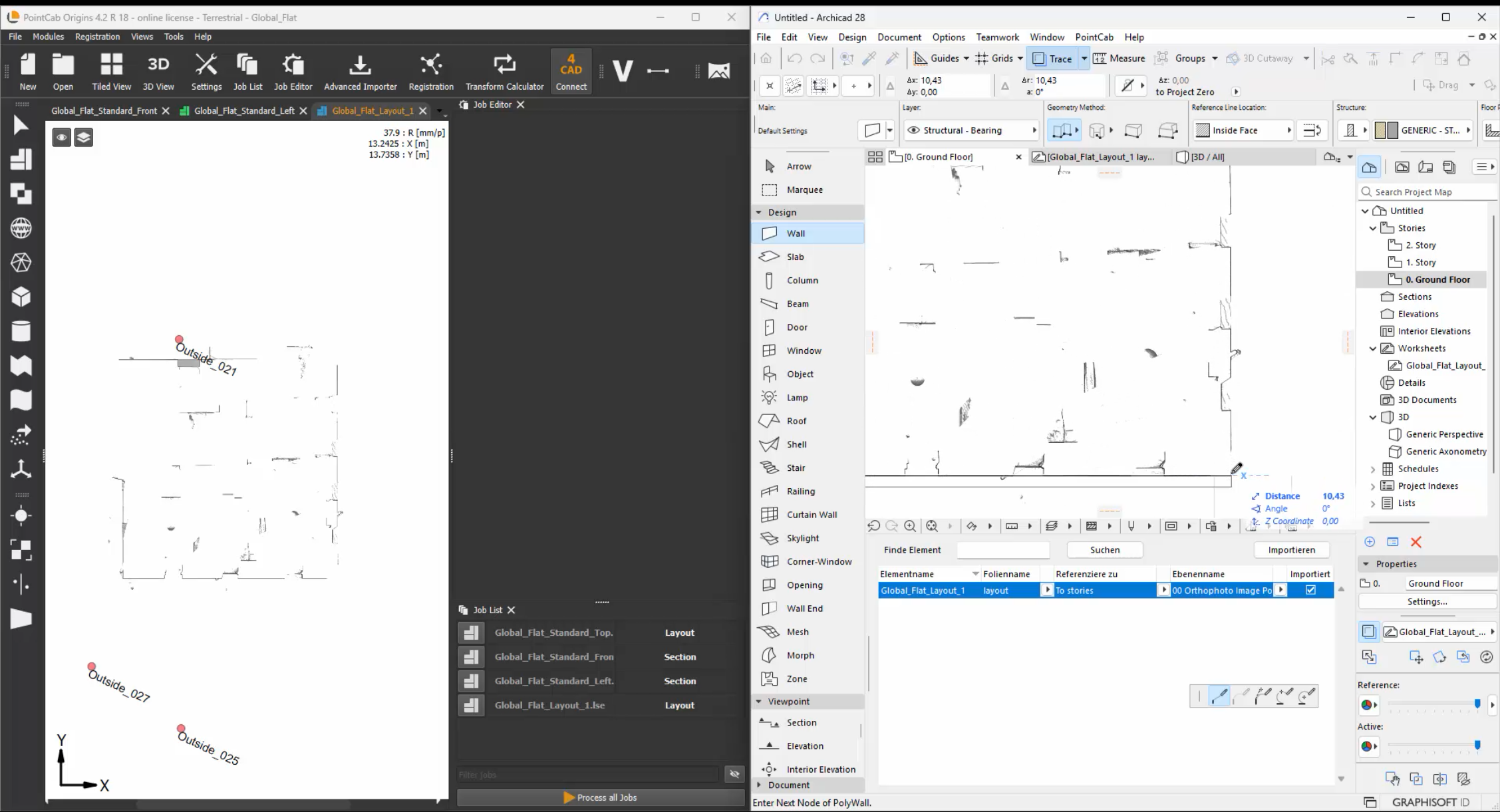
3. Model in Archicad Locally Now that your point cloud is positioned near the origin, you can safely and efficiently model in Archicad. Performance improves, and modeling tools behave as expected – without distortion caused by large coordinates.
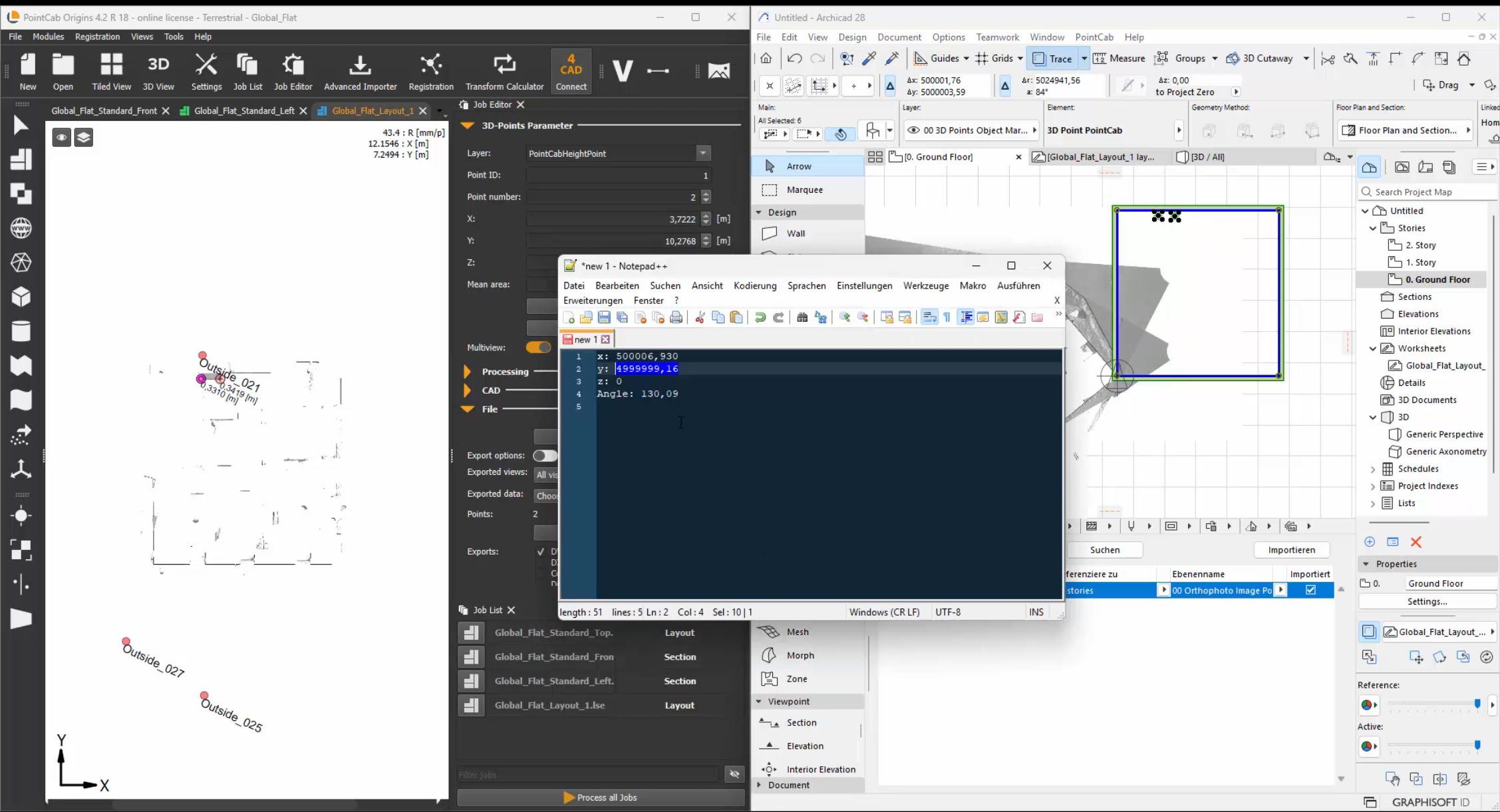
4. Re-Apply Georeferencing for Export After modeling, reverse the initial translation. This brings your model back to its true georeferenced location, ensuring your IFC, DWG, or BCF exports are correctly aligned in the real world
Bonus Tip: Forgot Your Transformation Settings?
No worries. Origins allows you to:
Create an Align transformation but not apply it right away. This shows you what changes would be made — which you can then reverse.
Alternatively, applying the same transformation twice can sometimes restore the original state (especially for pure translations).
Want to keep up with the latest pointCab news?
Then follow us on Social Media or subcribe to our newsletter!
Real-world support cases explained – one point cloud at a time.
In this series, we take a closer look at real questions and challenges that come up when working with point cloud data. Each post is based on an actual support case and breaks down what happened, why it happened, and how to solve it, step by step.
But we don’t stop at troubleshooting. Along the way, we explain the background behind the tools, terms, and technologies involved.
The Question That Sparked This Post
“I imported just one scan… why do I have over 900 files now?”
If that sounds familiar, you’re not alone, and no, PointCab isn’t secretly duplicating your data. This exact situation came up in a recent support case, and it gave us the perfect opportunity to explain what’s really going on behind the scenes.
Our customer imported a single E57 scan exported from Riegl’s RiSCANpro into PointCab Origins. The result:
Over 900 .lsd files created
More than 700 tiles visible in the Top View
And this was just one scan from a 30-scan project
The scan didn’t seem huge, so where did all those files come from? Let’s just say: it’s not a bug – it’s a feature. And a smart one at that.
The Key Context: Structured vs. Unstructured Point Clouds
Before diving into what happened, it helps to understand how point clouds are stored and why that matters when you import them into PointCab Origins.
Structured Point Clouds
Come directly from scanners in their native formats
Include metadata like scan positions and orientations
Organized into scan stations or lines, each with a defined perspective
Ideal for clean segmentation and accurate scan-to-scan alignment
Structured Point Clouds
Formats like E57, LAS, or LAZ (especially when exported generically)
Contain just the point data – no scan position, no segmentation
All points are merged into a single cloud, with no “origin story”
Often include stray points far outside the area of interest
Unstructured formats are great for software compatibility and flexibility, but they don’t tell the full story. That means software like Origins needs to rebuild structure to make the data usable. We explain this in more detail in our webinar on Structured vs. Unstructured Point Clouds, including why this difference affects file handling and performance.
What Origins Is Actually Doing
Now with this info in mind, let’s get back to the case at hand.
Origins doesn’t just render point clouds – it structures them so you can work with them efficiently.
Here’s what happens during import:
Origins breaks the entire point cloud into a 3D grid of cubes, known as an octree.
Each cube becomes a separate .lsd file, whether it contains thousands of points or just one.
These cubes are the foundation for views like the Top View, Section Views, and more.
If even one point lies far away from the main area, Origins generates all the intermediate cubes between that point and the rest of the data.
It’s kind of like paving a road to a remote cabin. You can’t just teleport there. Every step along the way needs to exist so the full path is usable.
What the User Saw
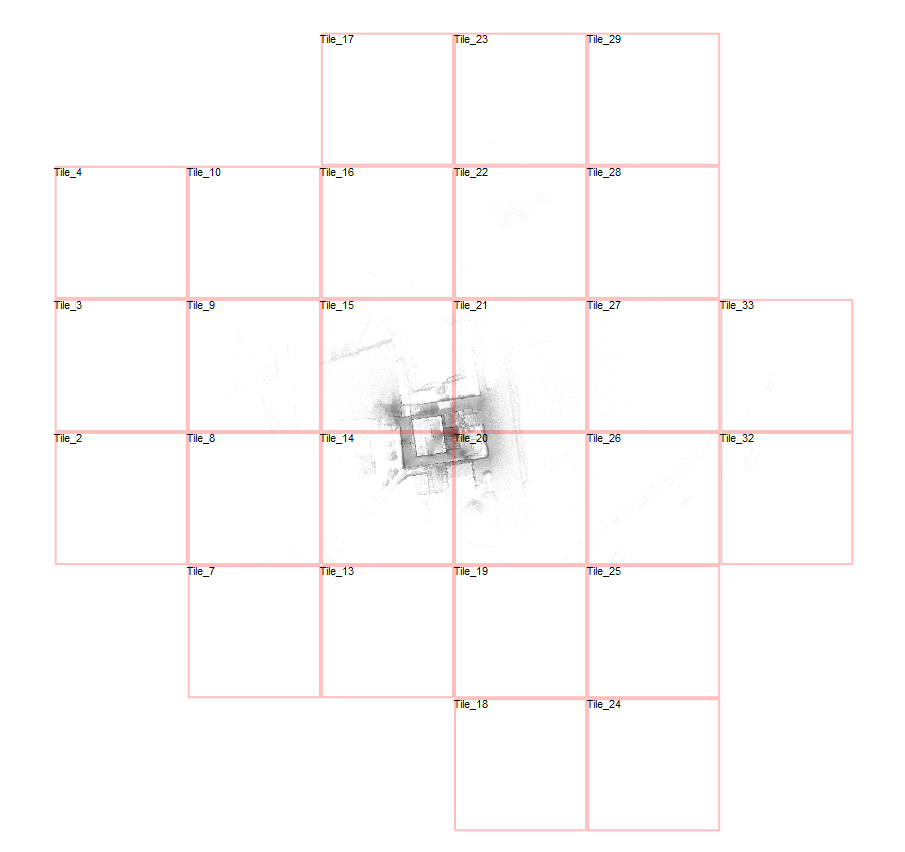
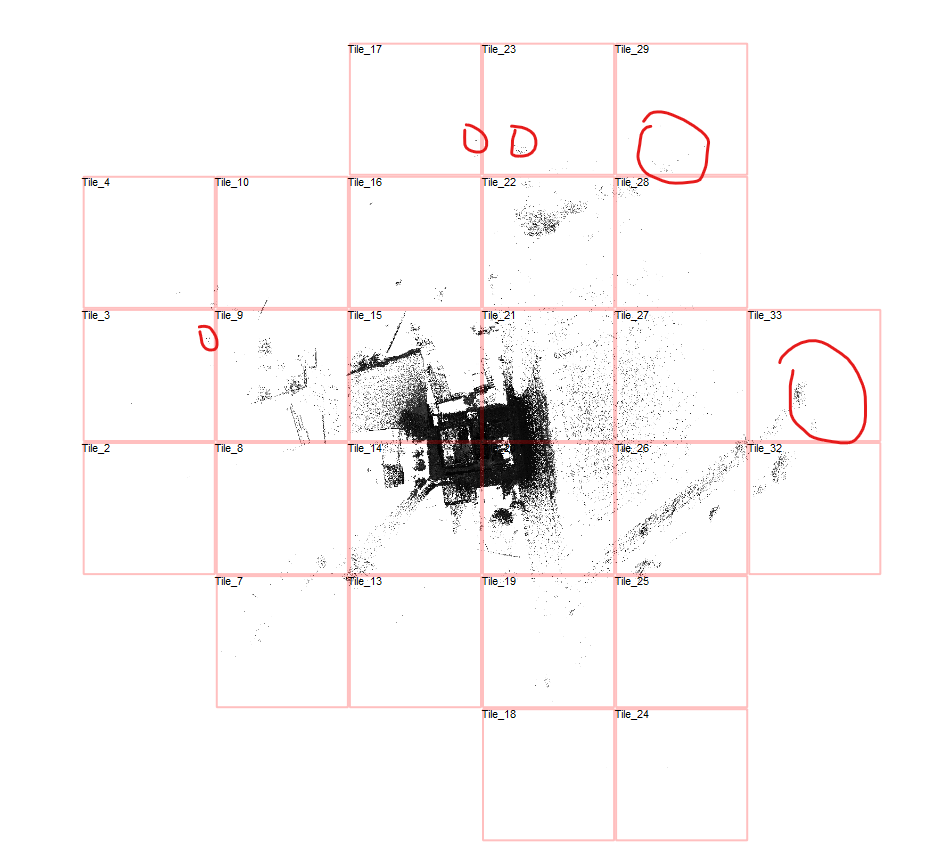
To understand the issue, we loaded the scan and pressed “B” in the Top View to toggle tile boundaries. The view showed:
A scan area stretching around 500 meters wide
And approximately 350 meters tall
So while the actual structure being scanned may have been compact, stray points – likely captured by the long-range scanner – extended the dataset much farther. And every bit of that range had to be included in the cube structure.
Is this a Problem and if so, how do I handle this?
Is this a problem? Not really. Origins handles large numbers of .lsd files efficiently. Most of them are very small in size, and they don’t slow down performance unless the scan range is extremely large or your hardware is struggling.
That said, a tighter Region of Interest can improve load times and keep your project folder cleaner, especially if you’re working with multiple scan areas or collaborating with others.
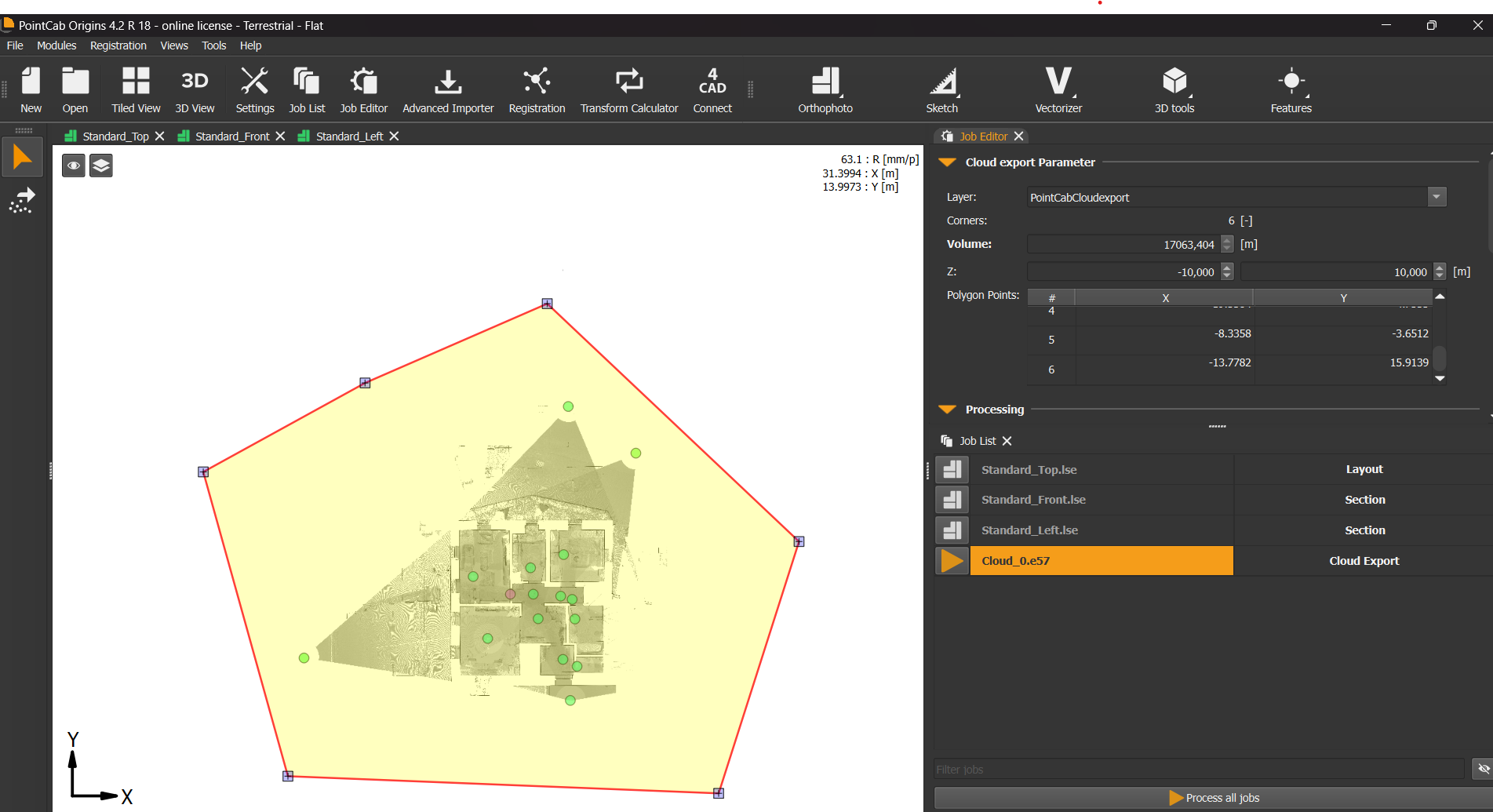
If you prefer a leaner project folder or faster loading times, you can reduce the number of files by tightening your import area: Import your scans into Origins as usual.
Use the point cloud export tool to select a focused Region of Interest.
Export just that area as a new point cloud.
Re-import the reduced file into a new PointCab project.
This keeps your file count – and disk space – under control while preserving all the data you actually need.
Final Thoughts
When a single scan suddenly turns into hundreds of files, it’s not Origins misbehaving – it’s Origins doing the hard work of organizing your data so you can actually use it.
If you’re ever unsure what’s going on behind the scenes, or want help optimizing your workflow, our support team is always happy to help. And if you want to better understand structured vs. unstructured data, check out our webinar on the topic.
Want to keep up with the latest pointCab news?
Then follow us on Social Media or subcribe to our newsletter!
As part of a student project at HTW Dresden, Jannes, a student of Geomatics, set out to answer a key question: How accurate is the Lixel L2 Pro mobile laser scanner from XGRIDS really? Together with Laserscanning Europe, he developed a comprehensive testing setup to evaluate the absolute geometric accuracy of the scanner in both indoor and outdoor environments. The tools PointCab Origins and CloudCompare played a central role in analysis, visualization, and validation.
Objective: Reliable Accuracy Through Comparison and Validation
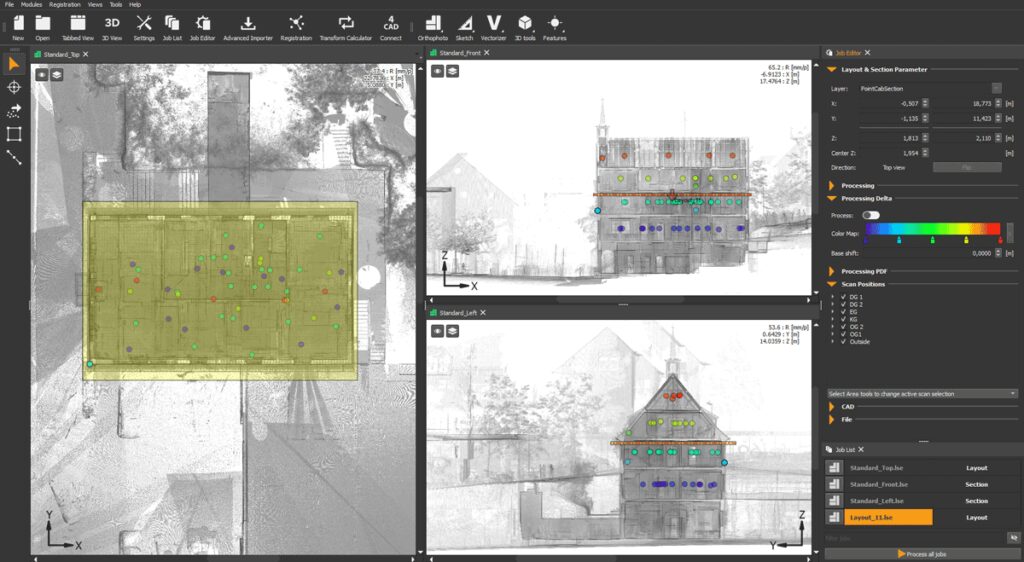
Distance and section analyses with PointCab Origins
The main question: Does the scanner meet the ±3 cm accuracy claimed by the manufacturer – and under what conditions?
Indoor Test: Controlled Conditions for Clear Results
In a hall at HTW Dresden, the L2 Pro was tested first without, then with, four control points. Faro checkerboard targets with known 3D coordinates were used to calculate spatial distances.
Results:
Without control points: Ø 9.2 mm deviation
With control points: Ø 5.3 mm deviation
Accuracy improvement through GCPs: ≈ 4 mm
Vertical accuracy – often problematic with mobile scanners – was also analyzed. In contrast to the smaller K1, the L2 Pro showed no significant vertical deviations, even in critical zones.
Analysis with PointCab Origins: More Than Just Visualization
In several sections at 5 mm resolution, barely any deviations were found between the L2 Pro cloud and the FARO reference. Only at highly reflective surfaces (e.g., ventilation ducts), deviations of up to 2.9 cm appeared – still within specification.
Good to know: Further Insight from the Field
Sebastian Zell, managing director of a Berlin-based specialist in architectural surveying, also underlines the importance of PointCab Origins for quality assurance:
“We use PointCab Origins to reliably and visually verify whether our point clouds are correctly registered – especially on large-scale projects.”
PointCab Origins proved invaluable in this project too: the software enables users to identify deviations at a glance – a key advantage for safe handover to CAD or BIM.
A 600 m loop was scanned using the L2 Pro to evaluate how the distribution of GCPs (Ground Control Points – permanently surveyed points in the field) affected results:
Scenario 1: GCP spacing < 100 m → RMSE horizontal: 2.6 cm | vertical: 0.4 cm
Scenario 2: GCP spacing > 100 m → RMSE horizontal: 3.2 cm | vertical: 1.2–1.5 cm
Scenario 3: Poorly distributed GCPs → RMSE vertical: up to 14 cm
Conclusion: a strategic and dense placement of GCPs is essential for overall accuracy – especially for mobile scanners using SLAM technology.
CloudCompare: Making the Numbers Visible
CloudCompare was also used alongside PointCab Origins to:
Directly compare point clouds (Cloud-to-Cloud Distance)
Visualize deviations using color mapping
Distinguish differences in mm and cm ranges
Result: The L2 Pro point cloud stayed well below the 3 cm tolerance across large areas, often under 1.5 cm – confirming its suitability for precise as-built documentation.
Conclusion: Quality Requires Verification – And the Right Tools
The project clearly shows: modern scanners like the L2 Pro can produce highly accurate results with the right workflow. But it’s only through tools like PointCab Origins and CloudCompare that the true reliability of the data becomes clear and measurable.
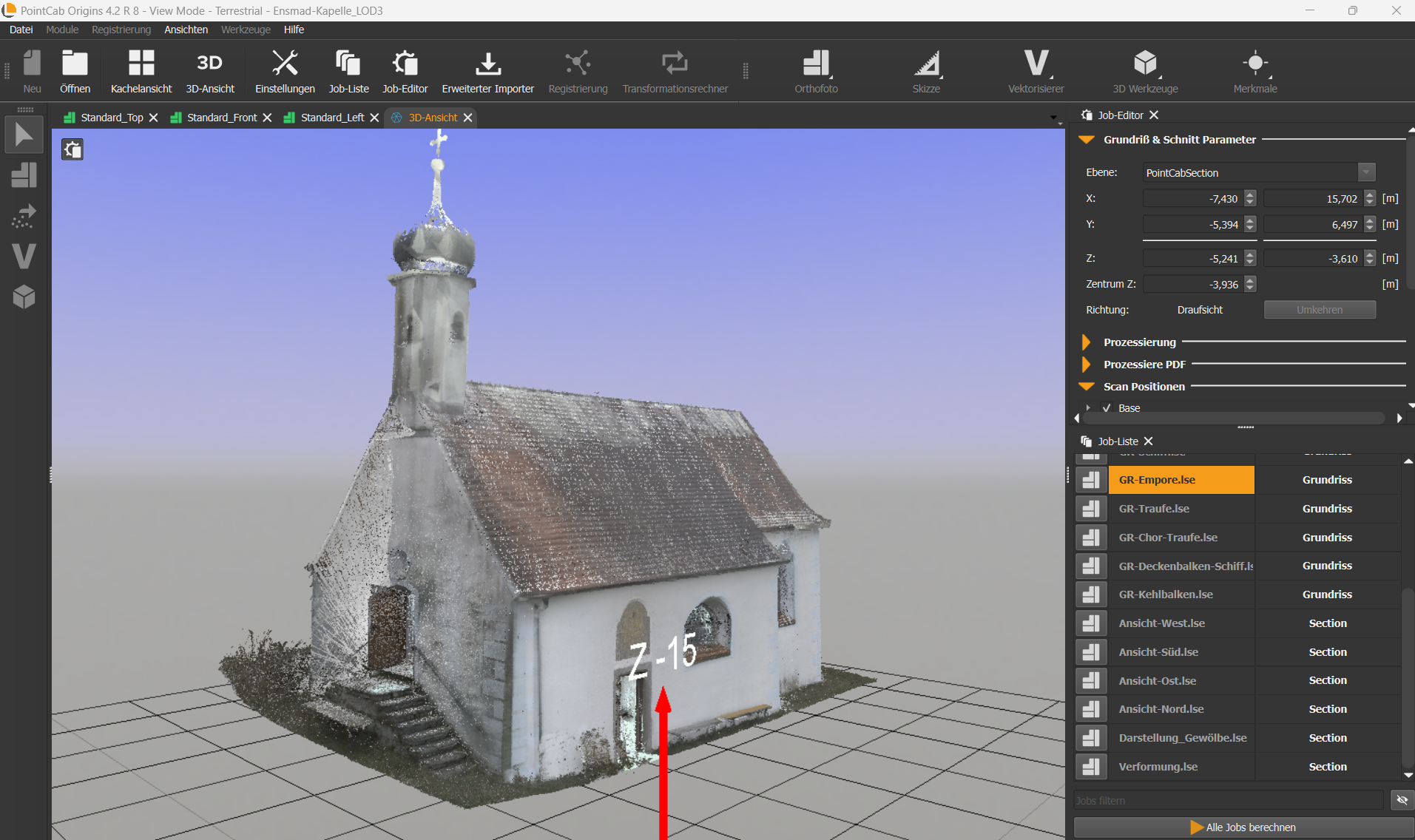
Daniel Bayha, a master’s student in Structural Engineering at the Stuttgart University of Applied Sciences, developed a digital workflow for his thesis to precisely document the historic Ensmad Chapel. His approach covered everything from the wooden barrel vault construction to the entire building condition – inside, outside, and within the roof space.
A key focus was not just the structural assessment of the timber construction, but also the creation of highly accurate deformation-based plans—a task that would have been nearly impossible with conventional manual measurement methods. To achieve this, modern laser scanning technologies were combined with specialized software solutions like PointCab Origins.
The Subject – Ensmad Chapel
Ensmad Chapel is a true cultural landmark and has been a pilgrimage site for centuries. Originally built in the Gothic style, it underwent a significant Baroque transformation around 1660 and has been lovingly maintained over the centuries, with the most recent renovation in the 1970s.
Today, the chapel shows visible structural damage that needed to be analyzed. Daniel’s goal was to document the current state of the building and create accurate plans to serve as a basis for future restoration efforts.
Data Collection & Hardware
Daniel opted for the FlexScan 22platform from Z+F as the hardware for data acquisition. The platform is equipped with the IMAGER 5016terrestrial laser scanner, which can be used both as a SLAM and as a static scanner. In addition, some details were measured manually to complement the data.
Scanning Duration: Approximately half a day on-site.
Challenges: Limited space, especially in the roof area. The FlexScan 22 had to be manually moved in this section, as it was not possible to walk through with a backpack scanner.
GOOD TO KNOW: COMBINING SLAM & TERRESTRIAL SCANNERS
The combination of SLAM and terrestrial laser scanners brings together the best of both worlds:
SLAM scanners allow for quick and mobile real-time data capture – ideal for large or hard-to-reach areas.
Terrestrial laser scanners provide precise measurements and detailed imaging of key areas.
This approach enables the creation of an initial rough map using SLAM, which is then refined with the precise terrestrial scan data. The result? Time savings, increased efficiency, and a comprehensive and reliable data foundation tailored to the specific application.
However, in this case, certain details were additionally measured by hand.
Data Processing & Plan Creation
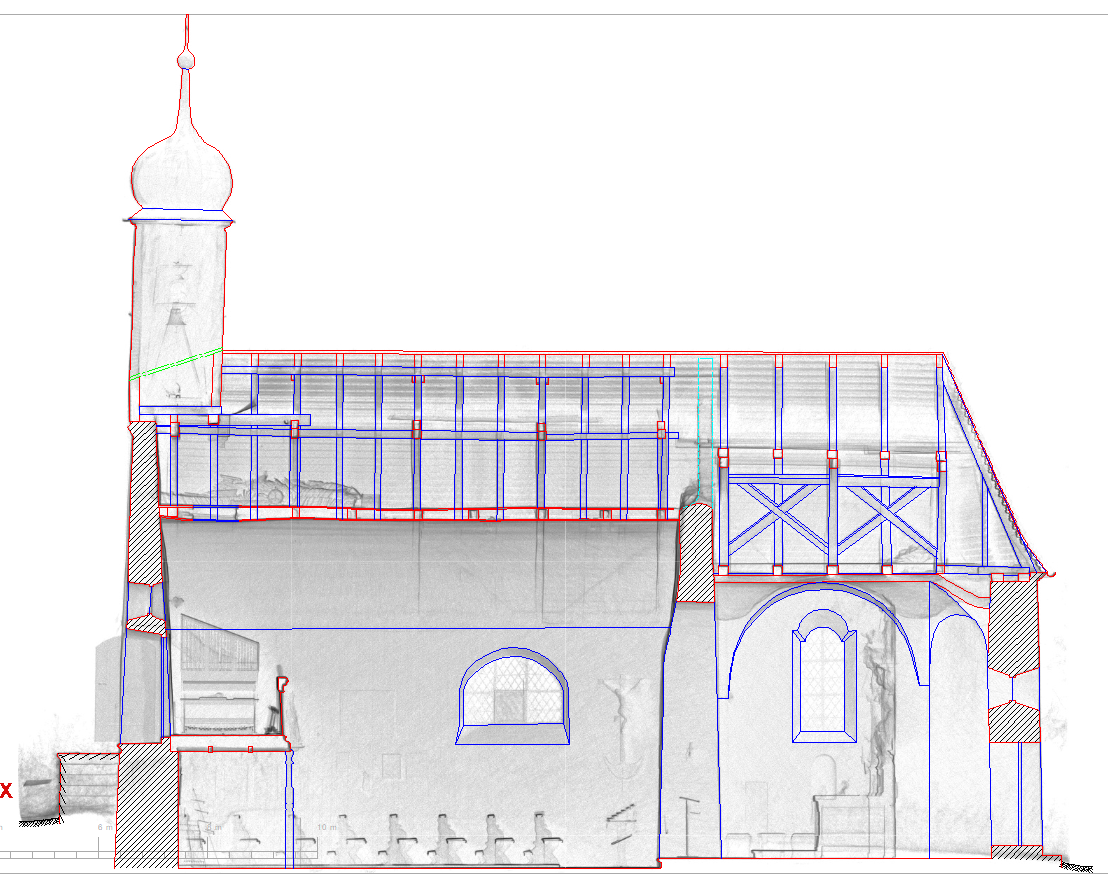
After data collection, erroneous points – such as those caused by passing individuals – were removed. This process took about a day and was conducted externally. The cleaned point cloud (in .E57 format) was then imported into PointCab Origins for further processing. Using PointCab Origins, 2D sections (cross-sections, longitudinal sections, and top views) were generated from the 3D data. Daniel needed about a day to familiarize himself with the software, followed by approximately two days to create the sections.
GOOD TO KNOW: HOW TO BECOME AN ORIGINS PRO (FAST)
With our YouTube tutorials and PDF guides on our website, Daniel was able to get started with Origins quickly and independently.
For those looking to become an Origins expert right away, we also offer a free demo session with our support specialists.
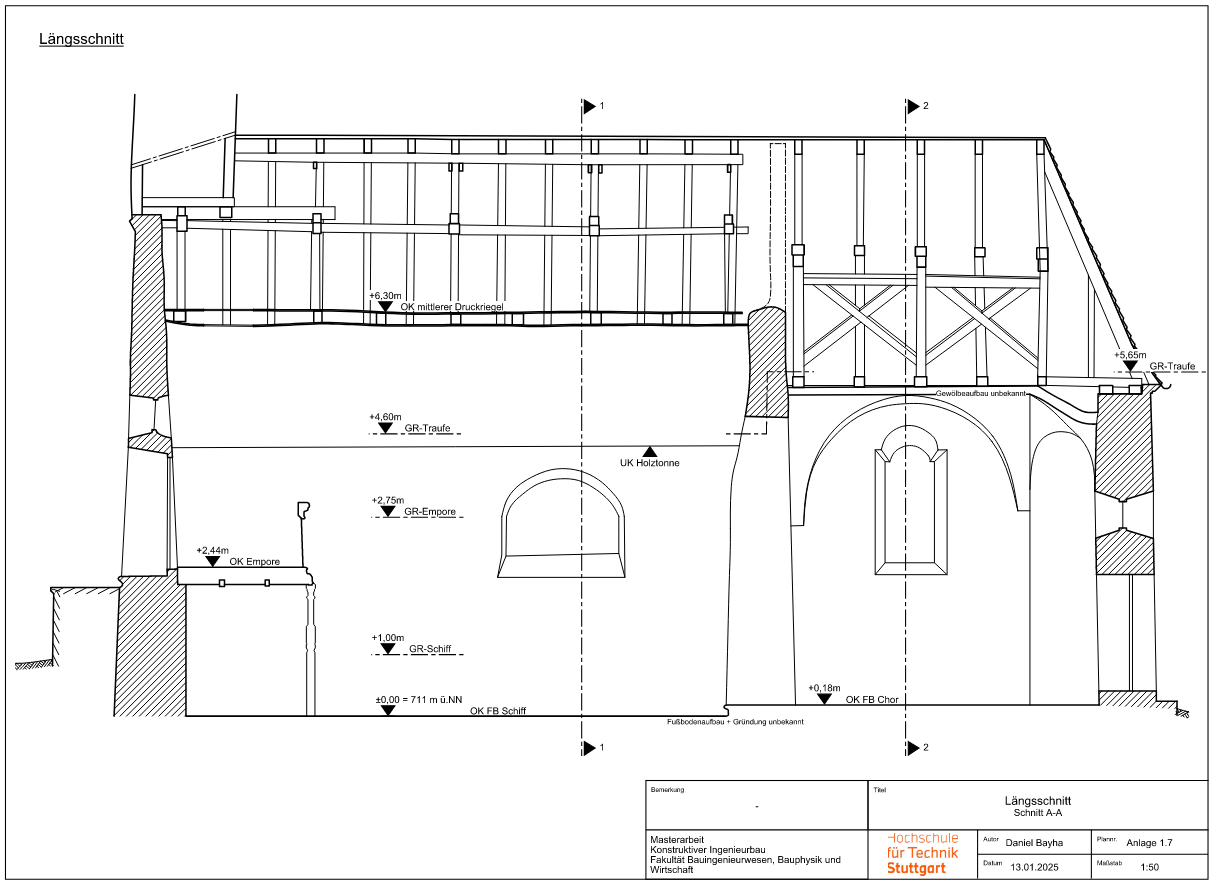
The plans were exported as PDFs, which were then imported into Nemetschek Allplan. There, Daniel manually redrew the plans, achieving an accuracy of ±3 cm.
Alongside Allplan, Bluebeam Revu Extreme was also used for further PDF data processing.
Total Time Required: The final plan creation took about a week in total.
TIP: DATA EXPORT
A faster workflow: If Daniel had exported the plans directly as planar .dwg files – automatically aligned and scaled for Allplan – he could have skipped the PDF export step, saving significant time.
Good to know: PointCab Origins is compatible with all major CAD programs and enables exports into their native formats. If you’re unsure about the best export option, our support team is always happy to help.
Conclusion & Key Takeaways
The Ensmad project impressively demonstrates how modern surveying technologies and specialized software solutions work together to digitally capture and prepare historic structures for restoration planning. Here are the key takeaways from the project:
1. Precision in Plan Creation: By combining modern laser scanning technology with PointCab Origins, it was possible to generate an unlimited number of highly accurate plans that faithfully reflect the chapel’s deformations and details.
2. Time and Work Efficiency: Despite some detours in the workflow, the project showed that complex surveying tasks can be completed efficiently with the right digital tools.
3. Optimization through Support: If users encounter workflow obstacles, they should reach out to PointCab Support. Often, alternative export methods or workflow optimizations can be quickly implemented together.
POINTCAB 2024:A YEAR OF GROWTH, INNOVATIONS & CELEBRATIONS
As 2024 comes to a close, we at PointCab are taking a moment to reflect on an exciting year filled with innovation, collaboration, and milestones. From significant product updates and thrilling events to team growth and anniversaries, this year has been one for the books. Let’s take a look back at what we’ve achieved together in 2024!
PRODUCT HIGHLIGHTS: PUSHING BOUNDARIES WITH POWERFULL UPDATES
2024 was a year of major releases and enhancements across the board. We introduced several updates that our workflows even more efficient and user-friendly:
4Archicad 2.0 & 2.1 (Windows & macOS): A huge step forward for Archicad users with powerful tools and seamless integrations.
4Brics, 4Revit, 4Autocad, and 4ZWCAD 2.1: Compatibility with the latest CAD versions has been established for all our plug-ins and new functions offer a more efficient workflow.
Origins 4.2: Featuring game-changing improvements, such as the GUI Docking System and a new License Manager, enhancing flexibility and usability.
Cross-Platform Releases: We made major strides with the releases for macOS, ensuring our software meets your needs no matter the platform.
Strengthening Connections: Events, Partners, and Resellers
2024 was a year of connections, both online and in person. We were proud to showcase our solutions at key industry events like GeoWeek USA, DigitalBAU in Köln, and Intergeo Expo in Stuttgart. These opportunities allowed us to connect with customers and partner alike, gain valuable insights, and share our latest innovations.
Collaboration remained at the heart of our growth. We were thrilled to present at the “IN TOWN” event with NavVis in Frankenberg, creating an inspiring atmosphere for exchange and new ideas. We also welcomed new resellers, including Dron-e Italy, GMX Systems LTD, and GEOZONA LTD, strengthening our global network and making PointCab solutions accessible to even more users worldwide.
A Decade of Success: Celebrating Our 10-Year Anniversary (Part 2)
This year marked a significant milestone for us: 10 years of PointCab! We celebrated this incredible journey with our team, partners, and friends at the beautiful Hohen Neuffen Castle. It was a moment to reflect on how far we’ve come and to celebrate the hard work, innovation, and dedication that brought us here.
A big thank you to everyone who has been part of this journey—your trust and support drive us to keep innovating and improving every day.
Team Growth: Building for the Future
Our team continued to grow in 2024. We welcomed two new developers to our team in Germany, bringing fresh ideas and expertise to help us deliver even more innovative solutions in the future.
We also took time to strengthen our bonds outside the office. From our unforgettable teambuilding event in Croatia to daily collaboration, our team remains the backbone of everything we do.
WHAT'S LEFT TO SAY?
THANK YOU!
2024 has been an incredible year of growth, milestones, and achievements. We’re deeply grateful to our customers, partners, and team members who make all of this possible. Your support inspires us to keep pushing boundaries and delivering the best solutions we can.
As we move into 2025, we can’t wait to show you what’s next. Stay tuned for more exciting updates, events, and partnerships as we continue to shape the future of our industry.
Thank you for being part of the PointCab family. Here’s to a bright and successful 2025!