

Punkt für Punkt
Ein Scan, 900 Dateien?!

Supportfälle aus der Praxis – verständlich erklärt, Punkt für Punkt.
In dieser Serie nehmen wir reale Supportanfragen unter die Lupe, die bei der Arbeit mit Punktwolkendaten auftauchen. Jeder Beitrag basiert auf einem echten Fall und zeigt Schritt für Schritt, was passiert ist, wieso es passiert ist und wie sich das Problem lösen lässt.
Dabei beschränken wir uns nicht nur auf die Fehlersuche. Wir liefern zusätzlich Hintergrundwissen zu wichtigen Themen, Tools und Technologien rund um Punktwolken.
Die Frage, die alles ins Rollen gebracht hat

„Ich habe nur einen Scan importiert … wieso habe ich plötzlich über 900 Dateien?“
Diese Frage hören wir nicht zum ersten Mal. Da uns aber genau so ein Fall kürzlich im Support wieder erreicht hat, liefert uns das die perfekte Gelegenheit zu erklären, was dabei eigentlich im Hintergrund geschieht. Kleine Beruhigung vorweg: Origins vervielfältigt Daten nicht einfach ungefragt.
Im konkreten Fall hatte unser Kunde einen einzelnen E57-Scan, exportiert aus Riegls RiSCANpro, in PointCab Origins importiert. Das Ergebnis:
- Über 900 .lsd-Dateien
- Mehr als 700 sichtbare Kacheln in der Top View
- Und das nur für einen Scan von insgesamt 30
Auf den ersten Blick wirkt der Scan allerdings recht überschaubar. Woher kommen also all diese Dateien? Die kurze Antwort: Das ist kein Fehler, sondern gewollt. Und durchaus sinnvoll.
Warum die Struktur der Punktwolke entscheidend ist
Um zu verstehen, was genau passiert, lohnt sich ein Blick auf den grundlegenden Unterschied zwischen strukturierten und unstrukturierten Punktwolken – denn der hat großen Einfluss auf die Verarbeitung in Origins.
Strukturierte Punktwolken
- Sind die nativen Dateiformate der verschiedenen Scanner
- Enthalten Metadaten wie Position und Ausrichtung der Scans
- Bestehen aus klar abgegrenzten Scanpositionen oder Linien
- Erleichtern die Segmentierung und exakte Ausrichtung der Scans untereinander
Unstrukturierte Punktwolken
- Typische offene Formate: E57, LAS, LAZ
- Enthalten nur die reinen Punktdaten – ohne Scanposition oder Strukturinformation
- Alle Punkte werden zu einer einzigen „Wolke“ zusammengeführt
- Häufig mit einzelnen Punkten weit außerhalb des eigentlichen Scanbereichs
Unstrukturierte Formate sind ideal für Software-Kompatibilität und Flexibilität. Sie enthalten aber keine Informationen darüber, wie die Punkte erfasst wurden. Daher muss Origins beim Import eine eigene Struktur aufbauen, damit sinnvoll mit den Daten gearbeitet werden kann.
Wer mehr über das Thema strukturierte und unstrukturierte Punktwolken wissen möchte, dem können wir übrigens unser Webinar dazu wärmstens empfehlen.
Was passiert eigentlich beim Origins Import?
Mit diesem Hintergrundwissen bewaffnet können wir uns nun wieder unserem eigentlichen Support-Fall widmen. Schauen wir uns an, was beim Import eines unstrukturierten Scans in Origins tatsächlich geschieht:
- Origins teilt die Punktwolke in ein dreidimensionales Rastersystem ein – ein sogenanntes Octree
- Jeder einzelne Rasterwürfel wird als .lsd-Datei gespeichert – egal ob er Tausende Punkte enthält oder nur einen
- Diese Würfel sind die Grundlage für alle Ansichten in Origins, z. B. die Standardansichten oder Schnitte
- Befindet sich auch nur ein einzelner Punkt weit entfernt vom Haupt-Scanbereich, erstellt Origins automatisch alle dazwischenliegenden Würfel, um diesen Punkt korrekt einordnen zu können.
Man kann sich das ein bisschen so vorstellen wie eine Straße zu einer abgelegenen Hütte: Selbst wenn dort nur ein Haus steht, muss der ganze Weg dorthin gebaut werden – sonst kommt man nicht hin.
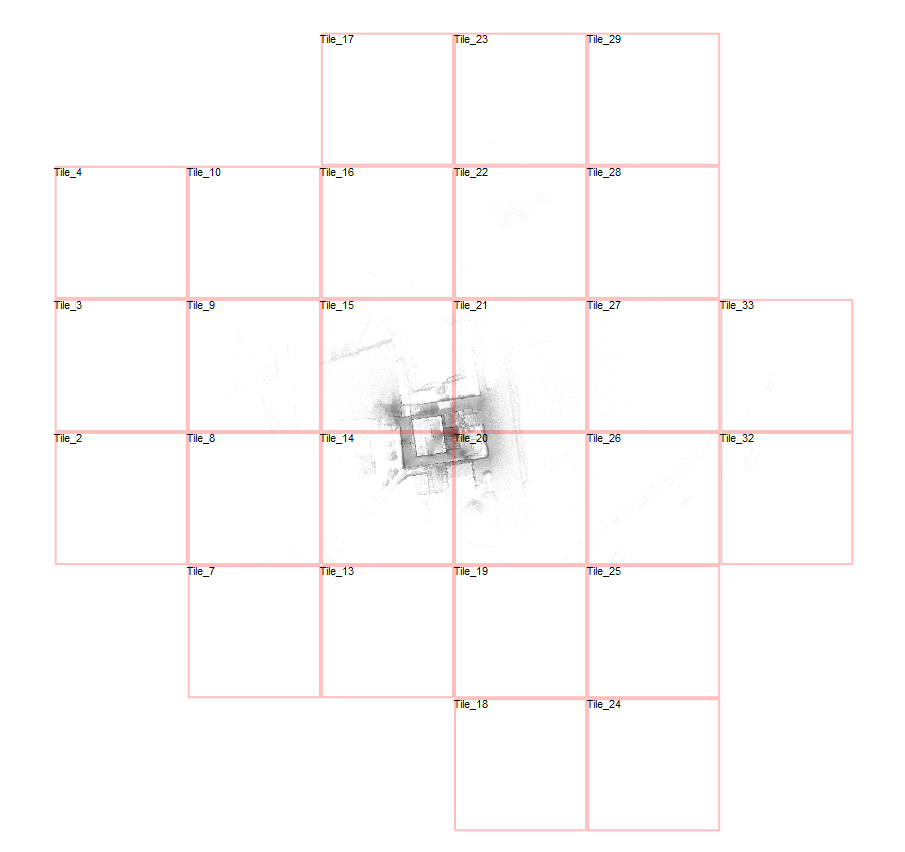
Was der Kunde schließlich sah
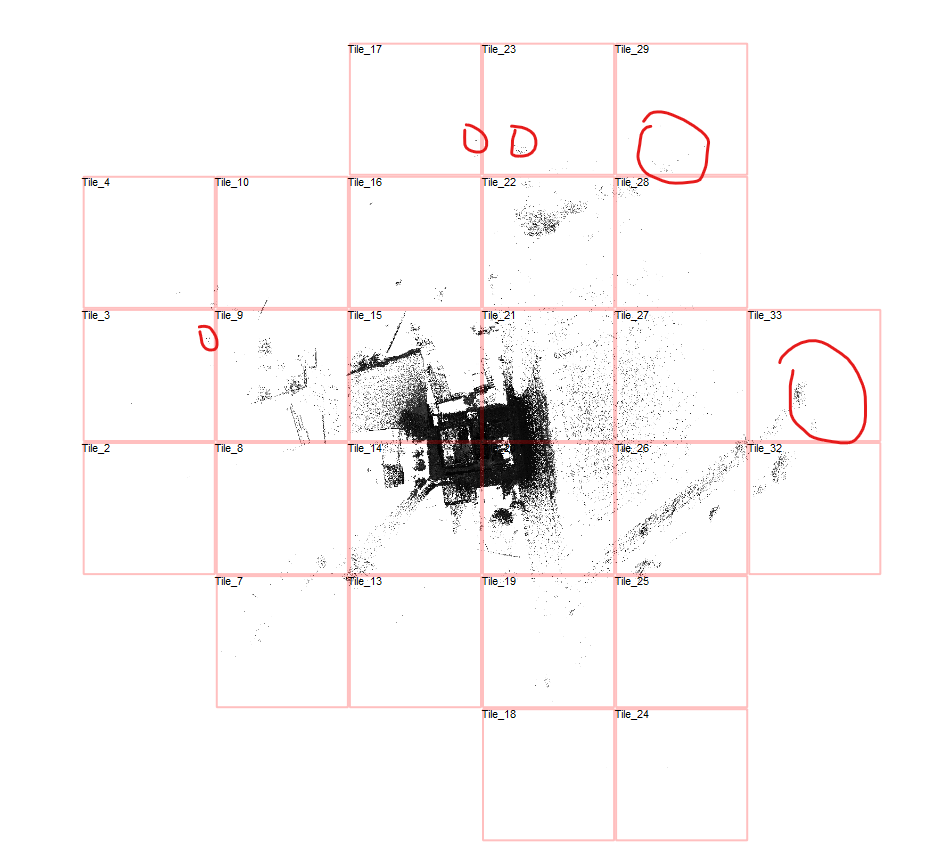
Um dem Ganzen auf den Grund zu gehen, wurde der Scan geöffnet und mit der Taste „B“ in der Top View die Kachelgrenzen sichtbar gemacht. Dabei zeigte sich:
- Der Scanbereich erstreckte sich über ca. 500 Meter Breite
- und etwa 350 Meter Höhe
Der eigentliche Zielbereich war zwar deutlich kleiner, aber durch einzelne, verstreute Punkte, musste die gesamte Umgebung mit abgebildet werden. Genau diese Punkte zogen dadurch eine große Zahl an zusätzlichen Kacheln – und damit Dateien – nach sich.
Ist das ein Problem? Und wenn ja, wie lässt es sich vermeiden?
Ist das ein Problem? In der Regel: Nein.
Origins verarbeitet auch große Mengen an .lsd-Dateien effizient. Die meisten davon sind sehr klein und wirken sich kaum auf Ladezeiten oder Speicherplatz aus – außer bei extrem großen Scanbereichen oder auf leistungsschwachen Rechnern.
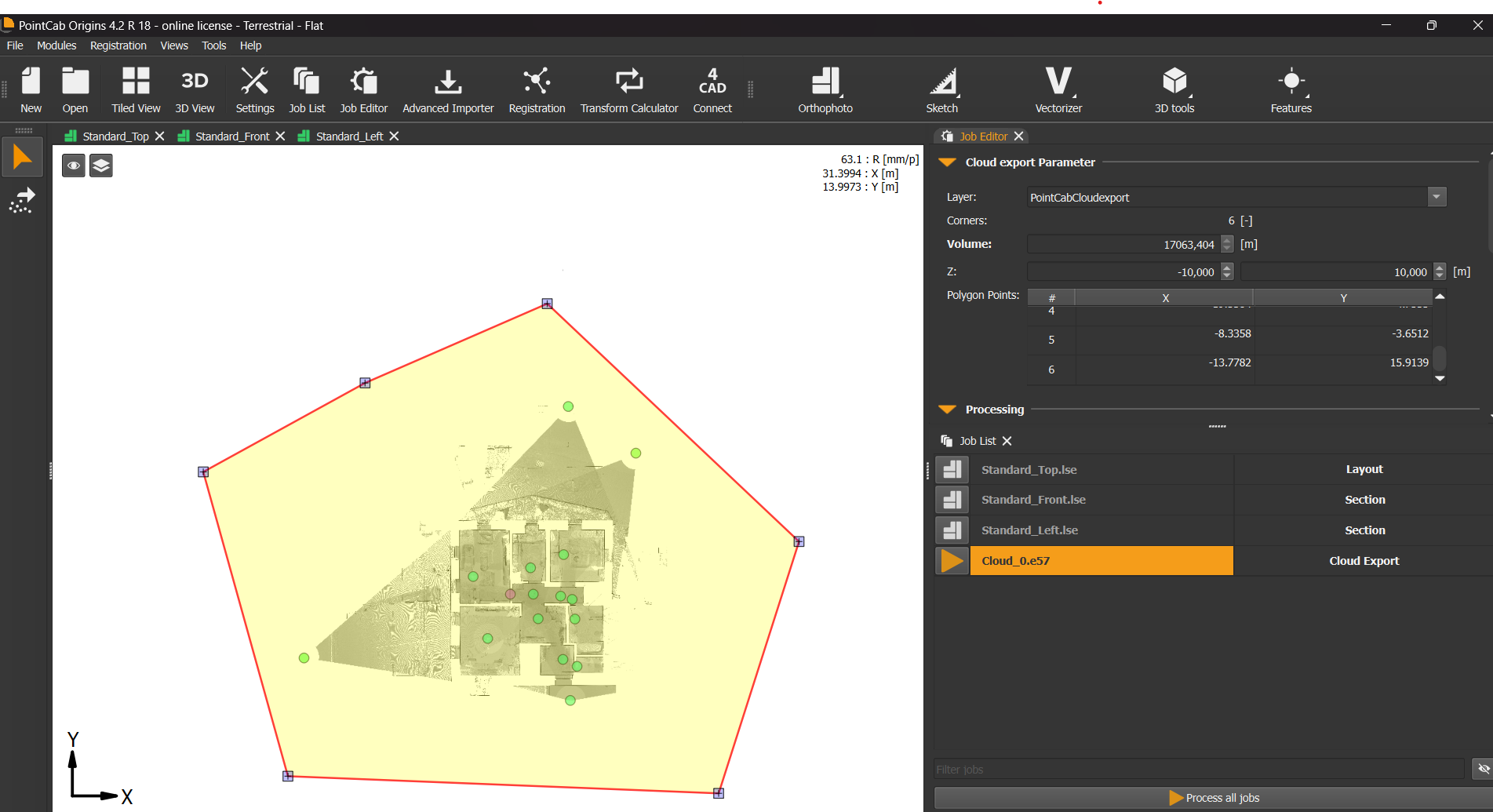
Wer allerdings Wert auf eine schlanke Projektstruktur und kürzere Ladezeiten legt, kann mit einem gezielten Workflow gegensteuern. So sieht der Workflow dafür aus:
- Scan wie gewohnt in Origins importieren
- Punktwolken-Exportwerkzeug nutzen, um gezielt den gewünschten Punktwolkenbereich auszuwählen und zu exportieren
- Neue, reduzierte Datei als neue Projekt importieren
Das Ergebnis: Weniger Dateien, geringerer Speicherbedarf, bessere Performance und trotzdem alle relevanten Daten im Blick.
Fazit
Wenn aus einem einzigen Scan plötzlich Hunderte Dateien werden, steckt kein Fehler dahinter – im Gegenteil. Origins sorgt dafür, dass Sie auch mit unstrukturierten Punktwolken zuverlässig und strukturiert arbeiten können.
Sie sind unsicher, was im Hintergrund passiert? Oder möchten Ihren Workflow optimieren? Unser Support-Team steht jederzeit gern zur Seite.
Und wenn Sie tiefer in das Thema einsteigen möchten: In unserem Webinar erfahren Sie, wie strukturierte und unstrukturierte Punktwolken wirklich funktionieren – und worauf es bei der Verarbeitung ankommt.
Sie wollen immer auf dem neusten stand bleiben?
Dann folgen Sie uns auf Social Media oder abonnieren Sie unseren Newsletter!